40 variational autoencoder for deep learning of images labels and captions
› csdl › proceedings2017 IEEE International Conference on Computer Vision (ICCV) Deep Clustering via Joint Convolutional Autoencoder Embedding and Relative Entropy Minimization pp. 5747-5756 Deep Scene Image Classification with the MFAFVNet pp. 5757-5765 Learning Bag-of-Features Pooling for Deep Convolutional Neural Networks pp. 5766-5774 Variational autoencoder for deep learning of images, labels and ... A novel variational autoencoder is developed to model images, as well as associated labels or captions. The Deep Generative Deconvolutional Network (DGDN) is used as a decoder of the latent image features, and a deep Convolutional Neural Network (CNN) is used as an image encoder; the CNN is used to approximate a distribution for the latent DGDN features/code.
Variational Autoencoder for Deep Learning of Images, Labels and Captions PDF - A novel variational autoencoder is developed to model images, as well as associated labels or captions. The Deep Generative Deconvolutional Network (DGDN) is used as a decoder of the latent image features, and a deep Convolutional Neural Network (CNN) is used as an image encoder; the CNN is used to approximate a distribution for the latent DGDN features/code.

Variational autoencoder for deep learning of images labels and captions
Variational Autoencoder for Deep Learning of Images, Labels and Captions A novel variational autoencoder is developed to model images, as well as associated labels or captions. The Deep Generative Deconvolutional Network (DGDN) is used as a decoder of the latent image features, and a deep Convolutional Neural Network (CNN) is used as an image encoder; the CNN is used to approximate a distribution for the latent DGDN features/code. The latent code is also linked to ... Variational Autoencoder for Deep Learning of Images, Labels and Captions Abstract. A novel variational autoencoder is developed to model images, as well as associated labels or captions. The Deep Generative Deconvolutional Network (DGDN) is used as a decoder of the latent image features, and a deep Convolutional Neural Network (CNN) is used as an image encoder; the CNN is used to approximate a distribution for the ... PDF Variational Autoencoder for Deep Learning of Images, Labels and Captions The model is learned using a variational autoencoder setup and achieved results ... Variational Autoencoder for Deep Learning of Images, Labels and Captions Author: Yunchen Pu , Zhe Gan , Ricardo Henao , Xin Yuan , Chunyuan Li , Andrew Stevens and Lawrence Carin
Variational autoencoder for deep learning of images labels and captions. Variational Autoencoder for Deep Learning of Images, Labels and Captions CiteSeerX - Document Details (Isaac Councill, Lee Giles, Pradeep Teregowda): Abstract A novel variational autoencoder is developed to model images, as well as associated labels or captions. The Deep Generative Deconvolutional Network (DGDN) is used as a decoder of the latent image features, and a deep Convolutional Neural Network (CNN) is used as an image encoder; the CNN is used to ... Variational autoencoder for deep learning of images, labels and captions A novel variational autoencoder is developed to model images, as well as associated labels or captions. The Deep Generative Deconvolutional Network (DGDN) is used as a decoder of the latent image features, and a deep Convolutional Neural Network (CNN) is used as an image encoder; the CNN is used to approximate a distribution for the latent DGDN features/code. Variational Autoencoder for Deep Learning of Images, Labels and Captions 摘要:. A novel variational autoencoder is developed to model images, as well as associated labels or captions. The Deep Generative Deconvolutional Network (DGDN) is used as a decoder of the latent image features, and a deep Convolutional Neural Network (CNN) is used as an image encoder; the CNN is used to approximate a distribution for the ... › library › view4. Major Architectures of Deep Networks - Deep Learning [Book] However, random forests and ensemble methods tend to be the winners when deep learning does not win. The input dataset size can be another factor in how appropriate deep learning can be for a given problem. Empirical results over the past few years have shown that deep learning provides the best predictive power when the dataset is large enough.
Variational Autoencoder for Deep Learning of Images, Labels and Captions A novel variational autoencoder is developed to model images, as well as associated labels or captions. The Deep Generative Deconvolutional Network (DGDN) is used as a decoder of the latent image features, and a deep Convolutional Neural Network (CNN) is used as an image encoder; the CNN is used to approximate a distribution for the latent DGDN ... Variational Autoencoder for Deep Learning of Images, Labels and Captions While large sets of labeled and captioned images have been assembled, in practice one typically encounters far more images without labels or captions. To leverage the vast quantity of these latter images (and to tune a model to the specic unlabeled/uncaptioned images of interest at test), semi-supervised learning of image features is of interest. PDF Variational Autoencoder for Deep Learning of Images, Labels and Captions A novel variational autoencoder is developed to model images, as well as associated labels or captions. The Deep Generative Deconvolutional Network (DGDN) is used as a decoder of the latent image features, and a deep Convolutional Neural Network (CNN) is used as an image encoder; the CNN is used to approximate a distribution Variational Autoencoder for Deep Learning of Images, Labels and Captions A novel variational autoencoder is developed to model images, as well as associated labels or captions. The Deep Generative Deconvolutional Network (DGDN) is used as a decoder of the latent image features, and a deep Convolutional Neural Network (CNN) is used as an image encoder; the CNN is used to approximate a distribution for the latent DGDN features/code...
Variational Autoencoder for Deep Learning of Images, Labels and Captions Abstract. A novel variational autoencoder is developed to model images, as well as associated labels or captions. The Deep Generative Deconvolutional Network (DGDN) is used as a decoder of the latent image features, and a deep Convolutional Neural Network (CNN) is used as an image encoder; the CNN is used to approximate a distribution for the latent DGDN features/code. direct.mit.edu › neco › articleA Survey on Deep Learning for Multimodal Data Fusion - MIT Press May 01, 2020 · Abstract. With the wide deployments of heterogeneous networks, huge amounts of data with characteristics of high volume, high variety, high velocity, and high veracity are generated. These data, referred to multimodal big data, contain abundant intermodality and cross-modality information and pose vast challenges on traditional data fusion methods. In this review, we present some pioneering ... Variational Autoencoder for Deep Learning of Images, Labels and Captions. Variational Autoencoder for Deep Learning of Images, Labels and Captions. Conference Paper. Full Text. Publisher Link; Duke Authors . Henao, Ricardo Reviews: Variational Autoencoder for Deep Learning of Images, Labels ... Reviewer 1 Summary. This paper presents a new variational autoencoder (VAE) for images, which also is capable of predicting labels and captions. The proposed framework is based on using Deep Generative Deconvolutional Networks (DGDNs) as a decoders of the latent image features, and a deep Convolutional Neural Network (CNN) as the encoder which approximates the distribution encoded by the VAE.
Building Web App for Computer Vision Model & Deploying to Production in ...
› help › deeplearningData Sets for Deep Learning - MATLAB & Simulink - MathWorks Discover data sets for various deep learning tasks. ... Train Variational Autoencoder ... segmentation of images and provides pixel-level labels for 32 ...
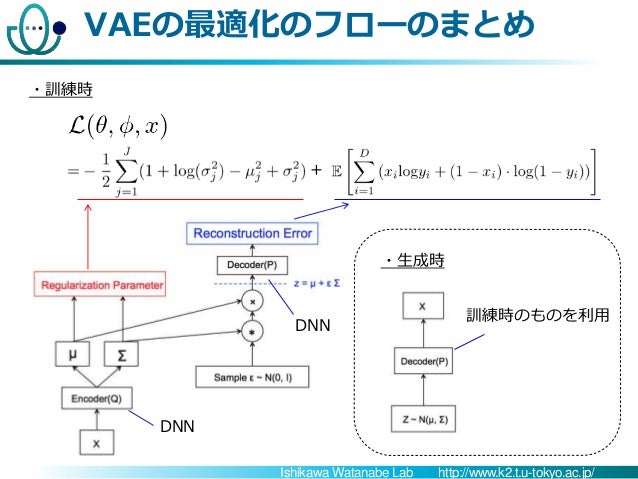
猫でも分かるVariational AutoEncoder
Variational Autoencoder for Deep Learning of Images, Labels and Captions A novel variational autoencoder is developed to model images, as well as associated labels or captions. The Deep Generative Deconvolutional Network (DGDN) is used as a decoder of the latent image features, and a deep Convolutional Neural Network (CNN) is used as an image encoder; the CNN is used to...

Variational Autoencoders as Generative Models with Keras | by Kartik ...
A robust variational autoencoder using beta divergence Abstract The presence of outliers can severely degrade learned representations and performance of deep learning methods and hence disproportionately affect the training process, leading to incorrec...

A plot of contrast-to-noise (a) and signal-to-noise (b) ratios compare ...
Variational Autoencoder for Deep Learning of Images, Labels and Captions Corpus ID: 2665144; Variational Autoencoder for Deep Learning of Images, Labels and Captions @inproceedings{Pu2016VariationalAF, title={Variational Autoencoder for Deep Learning of Images, Labels and Captions}, author={Yunchen Pu and Zhe Gan and Ricardo Henao and Xin Yuan and Chunyuan Li and Andrew Stevens and Lawrence Carin}, booktitle={NIPS}, year={2016} }

a Original image, b image with noise, c restored image using the 2-D RI ...
Variational Autoencoder for Deep Learning of Images, Labels and Captions A novel variational autoencoder is developed to model images, as well as associated labels or captions, and a new semi-supervised setting is manifested for CNN learning with images; the framework even allows unsupervised CNN learning, based on images alone. A novel variational autoencoder is developed to model images, as well as associated labels or captions. The Deep Generative ...

Most #AI mentions? 10 years of earnings transcripts show @Microsoft and ...
› science › articleGenerative adversarial network in medical imaging: A review Dec 01, 2019 · With the resurgence of deep learning in computer vision starting from 2012 (Krizhevsky et al., 2012), the adoption of deep learning methods in medical imaging has increased dramatically. It is estimated that there were over 400 papers published in 2016 and 2017 in major medical imaging related conference venues and journals ( Litjens et al ...
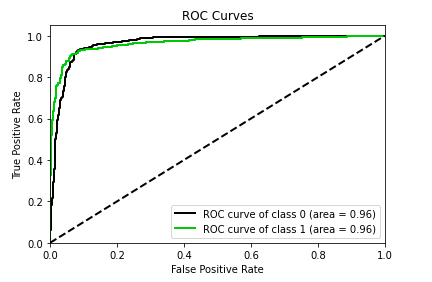
FaceMask Detection | Home
› tutorials › imagesImage classification | TensorFlow Core Jan 26, 2022 · This is a batch of 32 images of shape 180x180x3 (the last dimension refers to color channels RGB). The label_batch is a tensor of the shape (32,), these are corresponding labels to the 32 images. You can call .numpy() on the image_batch and labels_batch tensors to convert them to a numpy.ndarray. Configure the dataset for performance

a Original image, b image with noise, c restored image using the 2-D RI ...
Variational Autoencoder for Deep Learning of Images, Labels and Captions A novel variational autoencoder is developed to model images, as well as associated labels or captions. The Deep Generative Deconvolutional Network (DGDN) is...
Post a Comment for "40 variational autoencoder for deep learning of images labels and captions"